
해당 게시물은 "혁펜하임의 AI DEEP DIVE"를 수강하고 작성되었습니다.
https://welldonecode.tistory.com/139
기울기 소실 (Vanishing Gradient)
해당 게시물은 "혁펜하임의 AI DEEP DIVE"를 수강하고 작성되었습니다. 깊은 층의 layer를 갖는 인공신경망은 입력층으로 갈수록 미분이 작아지는 (기울기가 소실되는, 0으로 가는) 문제가 발생한
welldonecode.tistory.com
이전 게시물에서 기울기 소실의 문제는 activation의 미분 때문이다. 라고 했다.
이를 해결하기 위해 ReLU가 등장하였다.
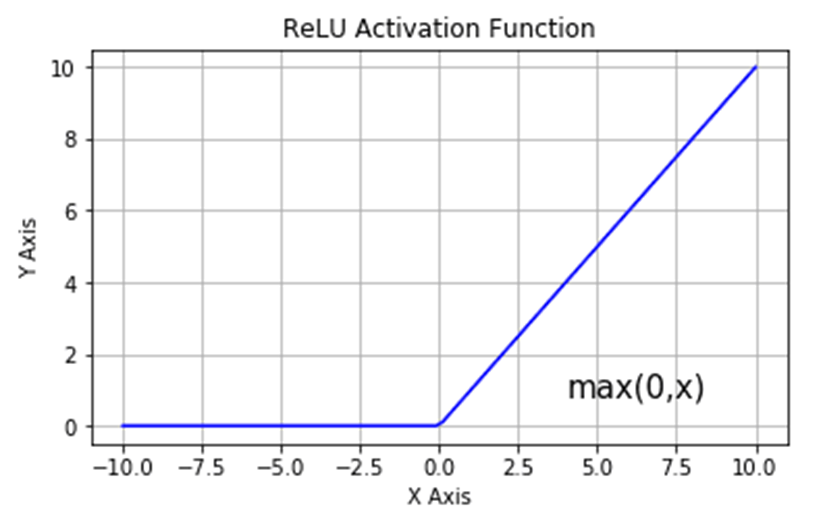
ReLU함수는 위 사진과 같이 0보다 작은 입력에 대해서는 0으로 출력하고, 0보다 큰 입력에 대해서는 입력과 같은 값을 출력한다.
그럼 양수인 입력에 대해서는 activation을 미분한 결과가 1이기 때문에 기울기 소실 문제는 해결된다.
그럼 음수는? 아예 0으로 보내버리는건 너무 가혹하다고 생각되는가? (음수가 있는 path를 모두 죽이게 됨)
이를 해결하기 위해 음수쪽의 기울기를 약간 살리는 leaky ReLU를 사용한다.
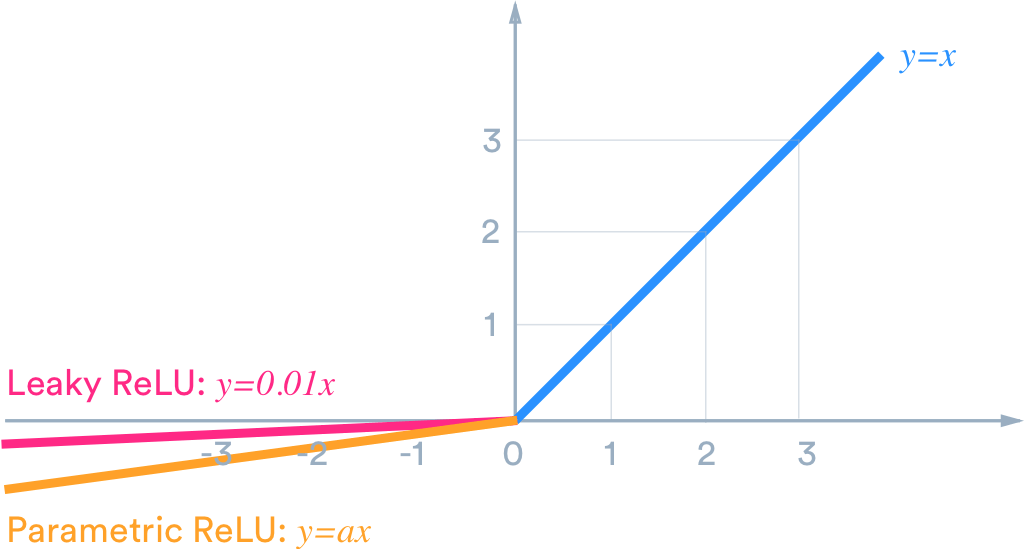
Leaky ReLU는 음수쪽 기울기를 0.01로 주기 때문에 activation 함수를 거친 출력이 0이 되는것을 방지한다.
해당 기울기를 학습을 통해 정하자는 것이 Parametric ReLU이다.
결국 위와 같은 함수들은 vanishing gradient의 문제도 없애고 non-linear한 activation function을 사용했을 때의 문제점 (은닉층이 없는 FC Layer의 표현력과 결국 같아지는 문제) 을 해결하고자 고안된 함수이다.
'AI' 카테고리의 다른 글
| Loss Landscape, Skip connection (0) | 2024.09.09 |
|---|---|
| Batch Normalization, Layer Normalization, Vanishing Gradient 해결 방안 정리 (0) | 2024.09.09 |
| 기울기 소실 (Vanishing Gradient) (0) | 2024.09.06 |
| Softmax를 이용한 다중 분류 (0) | 2024.09.05 |
| 딥러닝 학습의 본질 (MLE) (0) | 2024.09.05 |