
해당 게시물은 "혁펜하임의 AI DEEP DIVE"를 수강하고 작성되었습니다.
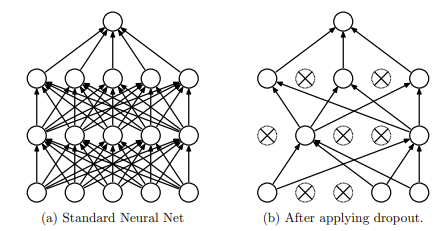
Overfitting 방지를 위한 방법중 하나는 Dropout이다.
이는 일부 노드를 가리면서 학습시키는 방법이다.
학습 시 노드들을 랜덤하게 가려서 학습시키고, 테스트 할 때는 이 결과를 평균내서 사용한다.
이러한 개념은 layer 별로 적용되고, 매 iteration마다 적용된다.

위 사진처럼, 학습 시에는 $p$의 확률로 노드를 살린다.
이는 각 데이터가 dropout을 적용시킨 레이어에 들어갈 때마다 다시 정해진다.
(데이터마다 dropout시킬 노드를 다시 고른다.)
테스트 시에는 모든 노드를 다 살린 후 weight에 $p$를 곱한다. (즉, 평균을 내는 느낌)
이는 학습 단계에서 dropout 확률만큼 노드가 비활성화 되어있는 점을 고려한 것이다.학습 단계에서 테스트 단계와는 다르게 상대적으로 많은 노드가 비활성화 되어 있기 때문에, 모든 노드가 활성화된 테스트 단계에서 학습 단계와 같은 scale을 가질 수 있도록 보정해 주는 것이다.

Dropout시 얻을 수 있는 또 다른 효과는 노드가 역할 분담을 잘 하게끔 한다는 것이다. (b)는 mnist 데이터에 대해서 노드 별로 특정 부분을 주의깊게 (weight를 많이) 보는 것을 확인할 수 있다.
이는 각 iteraion마다 특정 노드만 학습함으로써 해당 노드가 iteration의 downstream task의 특징을 잘 학습했다고 볼 수 있다.
다시 말해, Dropout을 적용하면 매 iteration마다 다른 신경망을 학습시키는 효과를 얻어 신경망을 골고루 학습시킬 수 있다. 이를 통해 풀고자 하는 문제인 downstream task에 대해 모델이 너무 편향되는 (일반화 성능이 떨어지는, 과적합되는) 문제를 해결한다.
'AI' 카테고리의 다른 글
| CNN (Convolution Neural Network) (1) | 2024.09.10 |
|---|---|
| Regularization (Overfitting 방지 방법) (0) | 2024.09.10 |
| Overfitting, Data augmentation (0) | 2024.09.09 |
| Loss Landscape, Skip connection (0) | 2024.09.09 |
| Batch Normalization, Layer Normalization, Vanishing Gradient 해결 방안 정리 (0) | 2024.09.09 |