![[논문리뷰] LLM4TS : Two-Stage Fine-Tuning for Time-Series Forecasting with Pre-Trained LLMs](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FSLJgQ%2FbtsDbettL1E%2FAAAAAAAAAAAAAAAAAAAAAIGO5UQzkh2PZr7A71Vlkpk3UuPMskFmykYrh1oUI12c%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1777561199%26allow_ip%3D%26allow_referer%3D%26signature%3D9wSwAxbRAzwV7YrT8Wm2Gl%252FECjw%253D)
[논문 링크]
https://arxiv.org/abs/2308.08469
LLM4TS: Aligning Pre-Trained LLMs as Data-Efficient Time-Series Forecasters
Multivariate time-series forecasting is vital in various domains, e.g., economic planning and weather prediction. Deep train-from-scratch models have exhibited effective performance yet require large amounts of data, which limits real-world applicability.
arxiv.org
시계열 데이터를 LLM으로 예측하여 높은 성능을 보인 흥미로운 논문이다.
아래의 논문 리뷰를 통해 그 내용을 살펴보겠다.
Summary
LLM4TS란?
- Large Language Model (LLM) 을 이용하여 시계열 데이터를 예측한다.
- Time-series Patching, Channel-independence 를 통해 모델의 input을 구성하여 LLM이 효과적으로 시계열 데이터를 다룰 수 있도록 한다.
- LLM을 fine tuning 하는 과정은 supervised fine-tuning, downstream fine-tuning을 통해 이루어진다.
- 광범위한 parameter의 조절 없이 연산량 감소 및 LLM 성능 향상을 위해 Parameter-Efficient Fine-Tuning (PEFT) 를 사용한다.
- 매우 제한된 훈련 데이터 (few-shot) 에서도 높은 성능을 보인다.
- 이러한 방법을 통하여 다른 모델 대비 MSE가 평균 6.2% 감소하는 성능을 보여준다.
Background
Time-Series Forecasting

•Long-term Time-Series 예측을 위해 사용되는 기법


Method
Motivation
- 기존의 시계열 데이터 자기 지도 학습에서는 CNN, RNN 기반의 백본 모델이 선호되고 있다.
- 이전 연구에서 사전 훈련된 LLM이 이미지, 오디오 및 시계열 데이터에서 충분한 잠재력이 있음을 보여줌에 따라 LLM4TS 모델로 시계열 데이터를 향상된 성능으로 예측하고자 한다.
Questions
- Time-Series 데이터를 이용하여 LLM을 어떻게 Fine-Tuning 할 것인가?
- Time-Series 데이터를 어떻게 LLM의 입력으로 넣을 것인가?
- LLM을 어떤 방식으로 학습시킬 것인가?
Model Architecture
- Time-Series 데이터를 이용하여 LLM을 어떻게 Fine-Tuning 할 것인가?
- Supervised, Downstream 2-Stage의 Fine-Tuning
- Time-Series 데이터를 어떻게 LLM의 입력으로 넣을 것인가?
- Patching, Channel Independence
- LLM을 어떤 방식으로 학습시킬 것인가?
- Layer Normalization tuning + Low-Rank Adaptation
1. Time-Series 데이터를 이용하여 LLM을 어떻게 Fine-Tuning 할 것인가?
-> Supervised Fine-Tuning (a)

2. Time-Series 데이터를 어떻게 LLM의 입력으로 넣을 것인가?
-> Instance Normalization
- Output이 Patch 형태이기 때문에 Denormalization 불가능.
- RevIN은 가중치, 편향 등의 파라미터를 사용하여 입력 데이터를 변환시킨다. 이는 원본 데이터를 왜곡시키고, 시간적 특성을 파괴하기 때문에 적합하지 않다.
위 사진에서 볼 수 있듯, Output이 Patch 형태이다.
-> Patching & Channel Independence - Tokenization

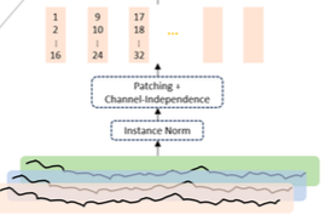
-> Token, Positional, Temporal Encoding
Temporal Encoding : 하나의 Patch 안에는 여러 timestamp 에 해당하는 데이터가 존재하는데 이를 하나의 통합된 표현으로 나타내기 위해 초기 timestamp를 해당 patch의 대표 timestamp로 지정.

3. LLM을 어떤 방식으로 학습시킬 것인가?


Experiments
Dataset
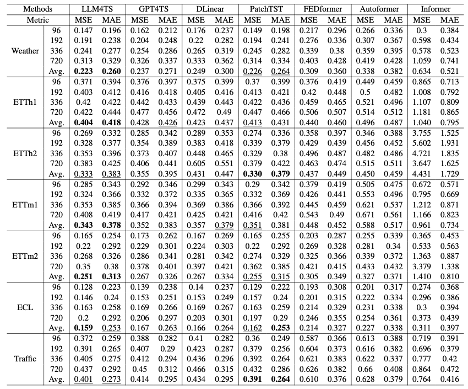
- MSE, MAE
- ”A Time Series is Worth 64 Words : Long-term Forecasting with Transformers” 논문의 실험 구성과 동일.
- GPT4TS의 구성과 동일하게 GPT-2의 12개 layer중 처음 6개 layer를 사용.
Default Setting
- Window Size : 336 or 512
- Patch length : 16
- Stride : 8
Self-supervised Learning Setting
- Window Size : 512
- Patch length : 12
- Stride : 12
Baseline
- Pre-trained LLM Model
- GPT4TS
- Transformer based Model
- PatchTST, FEDformer, Autoformer, Informer
- MLP based Model
- DLinear
Long-term forecasting for multivariate time-series data



Conclusion
- Pre-Train LLM (PLM) 을 사용하여 time-series 예측을 진행하는 LLM4TS 모델을 소개한다.
- Time-series 데이터를 LLM의 input으로 만들기 위해 Patching과 Channel Independence, token, positional, temporal encoding을 이용하였다.
- Time-Series 데이터의 특성을 모델이 잘 이해할 수 있게 Self-supervised fine-tuning을 진행하였다.
- ”예측” 이라는 목표에 모델이 맞춰지도록 Downstream fine-tuning을 진행하였다.
- Fine-tuning시, 연산 비용 감소와 성능을 향상을 위해 Layer Normalization Tuning과 LoRA를 이용하였다.
- 실험 결과, LLM4TS는 Long-term time-series forecasting과 입력 데이터로부터 유용하고 의미 있는 표현을 추출하여 학습하는 Representation learning에서 좋은 성능을 보이며 few-shot 상황에서도 좋은 성능을 보임을 증명하였다.