![[논문리뷰] LoRA : Low-Rank Adaptation of Large Language Models + 코드](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FbM8S0C%2FbtsF41k0u8t%2FAAAAAAAAAAAAAAAAAAAAAMwH4DIJeTFoWL71-zcqmYQiuaiFlz4hd6K4GHng4iL_%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1777561199%26allow_ip%3D%26allow_referer%3D%26signature%3DboPEF5AQqGSH2z77trIK8LIFNr4%253D)
https://arxiv.org/abs/2106.09685
LoRA: Low-Rank Adaptation of Large Language Models
An important paradigm of natural language processing consists of large-scale pre-training on general domain data and adaptation to particular tasks or domains. As we pre-train larger models, full fine-tuning, which retrains all model parameters, becomes le
arxiv.org
LoRA : Low-Rank Adaptation of Large Language Models 논문에 대한 리뷰를 진행한다.
Background
Rank란?
논문에 제목에서 확인할 수 있듯, Low-Rank에서 Rank란 무엇을 의미하는 것일까?
A라는 행렬의 Column rank는 Column space의 차원을 의미하고 Row rank는 Row space의 차원을 의미한다.
결국 행에서 선형 독립인 벡터의 개수와 열에서 선형 독립인 벡터의 개수를 구분해서 정의하겠다는 소리다.
Rank(A) = Min(n,m) 과 같은 수식으로 나타낼 수 있는데, 선형 독립인 행벡터의 개수, 선형 독립인 열벡터의 개수 중 작은 것이 A 행렬의 rank로 정해진다.
해당 논문에서는 행의 개수, 열의 개수 중 작은 것이 rank가 되고, 그 rank를 줄여서.. 즉, 행렬의 모양을 축소시켜서 무언가를 하겠다는 것이다.
Fine Tuning이란?
Fine tuning
fine tuning에 대한 정의도 알아두어야 한다.
이는 사전 훈련된 모델을 새로운 데이터나 작업에 맞게 적응시키는 것으로, 특히 특정 작업에 맞게 모델을 전문화시키는데 사용된다.

(x, y) : input, output
Z : 전체 데이터셋
P~ : LLM 모델을 나타내는 확률함수
Φ : LLM 모델의 파라미터
위 수식에서 알 수 있듯, 로그 우도함수를 사용할 때 최적의 파라미터 Φ를 찾을 확률을 최대화 시키기 위해서 동작한다.물론 전체 파라미터 Φ에 대해 모두 탐색하게 되어 무거운 모델의 경우 매우 높은 연산 코스트와 시간이 소요되는 단점이 존재한다.
How do we find the optimal value of Φ?
그렇다면 우리는 어떻게 최적의 Φ값을 찾을까?일반적인 방법론은 경사하강법(Gradient Descent)이다.cross entropy 혹은 다른 loss fuction을 최소화 하기 위해 동작한다.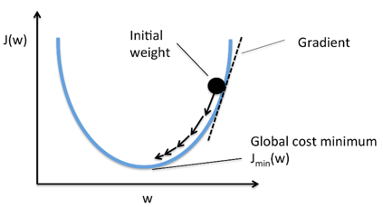
하지만 해당 방법에도 단점은 존재한다.
- 기울기(gradient)를 계산하기 위해 텐서들이 GPU의 VRAM 같은 곳에 저장되어야만 한다.
- momentun, adapted와 같은 기술을은 이전의 상태를 저장할 필요가 있다. (예. Optimizer State)
위와 같은 이유로 인하여 GPT3 모델의 경우 Φ = 1750억개 인데 이를 모두 학습시키기 위해서는 엄청난 자원이 필요하다.
Problem Statement
Parameter-efficient approach
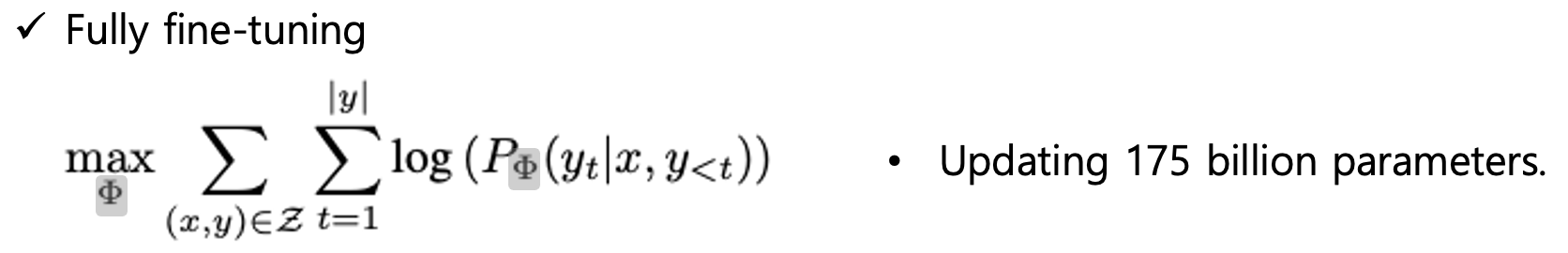

full fine tuning의 경우 모든 파라미터를 업데이트 해야 한다는 단점이 있지만,
논문 저자의 접근법은 아주 작은 파라미터 셋 Φ0와 델타만 업데이트 하게 되어 모든 파라미터를 업데이트 하는 것 보다 엄청난 코스트 감소 효과를 기대할 수 있다.
Introduction
When we use LoRA

- 사전 훈련된 가중치를 동결시킨다.
- Adaptation 과정에서 rank r 로 분해된 행렬로 Dense layer를 수정한다.
이로 인해 Dense layer의 일부만을 훈련시킬 수 있게 된다.
그렇다면 이게 왜 동작하는 것일까? 그 근거에 대해 알아보자.
An over-parameterized model exists with a low intrinsic dimension
쉽게 얘기하면 GPT3와 같이 엄청나게 많은 파라미터를 가지고 있는 모델은, 실제로는 적은 파라미터만으로도 존재할 수 있다는 것이다.


figure 1은 table 1의 DID 부분을 시각화한 것이다.
figure 1의 점선이 전체 파라미터를 가진 모델의 정확도를 나타내고, 꺾인선 그래프가 각각의 모델을 나타낸다.
x축은 실제로 사용할 학습 가능한 파라미터의 개수이며 로그스케일로 표현되어 있다.
y축은 모델의 정확도를 나타낸다.
MRPC에서 RoBERTa-Large 모델의 경우 단 322개의 파라미터,
QQP의 경우 단 774개의 파라미터 만으로도 전체 파라미터를 가진 모델 대비 약 90%의 성능 gain을 달성하는 것을 알 수 있다.
실제로는 적은 파라미터 만으로도 모델이 잘 동작할 수 있다는 것이다!
이를 근거로 저자가 제시한 일부 Dense Layer만 학습시킨다는 말이 터무늬없는 말이 아닌 것을 알 수 있다.
Method
Low_rank Parametrized Ipdate Matrices
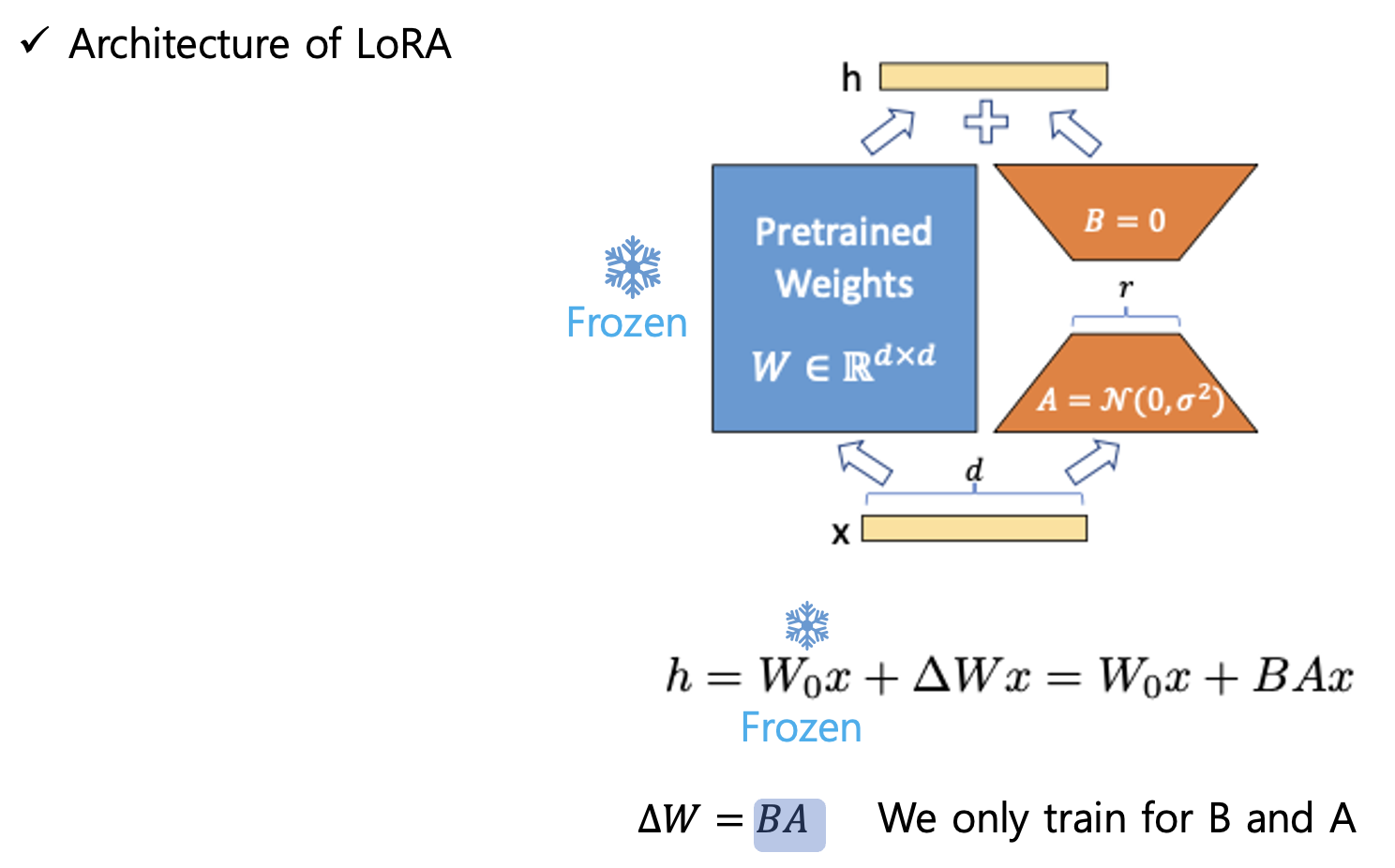
논문 저자의 접근법은 아주 작은 파라미터 셋 Φ0와 델타만 업데이트 하게 되어 모든 파라미터를 업데이트 하는 것 보다 엄청난 코스트 감소 효과를 기대할 수 있다.
라고 언급하였는데, LoRA에서는 파라미터 셋 Φ0도 동결시켜버린다. 우리는 델타에 해당하는 A행렬과 B행렬만 업데이트 할 것이다.
What is Transformer? What is q, k, v?
LoRA는 주로 Transformer 기반 모델과 같이 사용되는 경우가 많기 때문에 Transformer 모델이 무엇인지 간단히 소개한다.

- 트랜스포머 모델은 input sequence에 해당하는 단어와 단어 사이의 상관관계를 파악하기 위해 Attention Mechanism을 사용한다.
- 이는 장기 기억 의존성을 해결하며 병렬 처리를 효율적으로 가능하게 한다.
- 트랜스포머 모델은 인코더와 디코더 구조로 이루어진다.
- 인코더와 디코더의 각 레이어는 여러개의 어텐션과 피드포워드 계층으로 이루어진다.
- 이렇게 만들어진 모델은 다양한 자연어 처리 작업, 예를 들어 번역, 요약, 질의응답 같은 작업에 사용된다.

- Query (Q) : 질문
- Key (K) : 키
- Value (V) : 값
학습 과정에서 해당 Q, K, V 가중치를 조절하면서 모델이 단어의 상관관계와 연관성을 이해하도록 한다.
LoRA with Transformer

사진에서 보이는 Wq, Wk, Wv를 동결시킨 채, 해당 계층에 LoRA를 사용하여 연산 코스트를 획기적으로 낮추는 방법을 사용한다.
그렇다면 어떤 가중치를 동결시켰을 때 가장 효과적으로 동작할까?

Wq, Wv, r=4일때, 그리고 전체를 동결시키고 rank=2일때 가장 효과적으로 동작한다.
이를 통해 실제로 r도 그렇게 클 필요는 없다는 것을 알 수 있다.
Experiments

LoRA를 사용했을 때 SOTA를 달성했을 뿐만 아니라, GPT-3의 0.01%의 파라미터만을 사용해서 full-fine tuning과 거의 동등한 성능, 혹은 그에 상회하는 성능을 보여주고 있다.
Code


외 코드에서 생성자를 호출하고

위 코드에서 r이 0보다 클때 lora_A, lora_B 레이어를 초기화한다.
scaling은 두 가중치 행렬을 결합할 때 사용되는 scaling factor이다.
requires_grad를 False로 설정하여 사전 훈련된 가중치 행렬을 동결시킬 수 있다.
이때, A 레이어는 랜덤 가우시안 방법으로 초기화시키며, B 레이어는 0으로 초기화시킨다.

forward 연산에서 A와 B 행렬간의 행렬곱이 이루어진다.
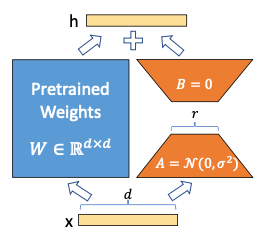
위 구조에서, A나 B 행렬 값이 너무 크거나 작으면 h도 극단적으로 크거나 작게 연산된다.
학습 안정성과 편향을 방지하기 위해 Q, K, V에 LoRA를 적용시킬 때 스케일링을 진행하게 된다.