
LLM이 생성한 (예측한) 결과를 평가하기 위해 PPL (Perplexity) 도 쓰이지만, 그보다 BLEU Score를 더 많이 사용한다.
PPL은 쉽게 말해 모델이 정답을 예측할 때 헷갈려하는 정도이다. 따라서 작으면 작을수록 좋다.
5개의 선택지 중 고민하는 것 보다, 2개의 선택지 중 고민하는게 모델이 그만큼 똑똑하다는 것이니까.
하지만, 번역 작업을 예로 들면, 우리는 문장의 맥락을 고려해서 번역이 잘 되었는지를 평가하고 싶어 한다.
해당 평가에 BLEU Score를 사용한다.
BLEU란?
$BLEU = BP\cdot \prod_{n=1}^{N}p_{n}^{w_{n}}$
로 계산되는 Evaluation Score이다.
- $p_{n}$ : n-gram precision
- $w_{n}$ : weight, 합=1
- $BP$ : Brevity (짧음) penalty
n-gram 이란 무엇인가?
정답 : "나는 정말로 훌륭한 학생 일까요"
예측 : "나는 정말 훌륭한 학생 입니다"
라는 문장을 예로 들어 보자.
1-gram : 나는 / 정말 / 훌륭한 / 학생 / 입니다
2-gram : 나는 정말 / 정말 훌륭한 / 훌륭한 학생 / 학생 입니다
3-gram : 나는 정말 훌륭한 / 정말 훌륭한 학생 / 훌륭한 학생 입니다
4-gram : 나는 정말 훌륭한 학생 / 정말 훌륭한 학생 입니다
이런 식으로 문장 안에서 n개의 연속된 단어 쌍을 의미한다.
n-gram precision은 아래와 같은 수식으로 나타낼 수 있다.
$\frac{정답 문장에 존재하는지 여부의 합계}{예측 문장의 n-gram 개수}$
위 문장에서 1-gram precision은 $\frac{3}{5}$ 이 된다.
하지만,
정답 : "훌륭한 나는 정말로 훌륭한 학생 일까요"
예측 : "훌륭한 나는 정말로 훌륭하게 훌륭한 학생 입니다"
위와 같은 경우 분명 이상한 문장인데, 점수가 높게 나올 수 있다.
Clipping
이를 예방하기 위해 Clipping이 필요하다. Clipping은 "훌륭한" 이라는 단어가 정답에 두번만 나오니, 1-gram precision을 할 때 해당 단어는 두번 까지만 count하여 점수를 보정한다.
BP
마지막으로 BP (Brevity penalty) 즉, 짧음 패널티를 곱해줘야 한다.
정답 : "훌륭한 나는 정말로 훌륭한 학생 입니다"
예측 : "학생 입니다"
위와 같은 경우 BP를 제외하고 계산하면 점수는 1이 나온다. 분명 예측은 잘못되었지만 말이다.
BP는 아래와 같이 계산한다.
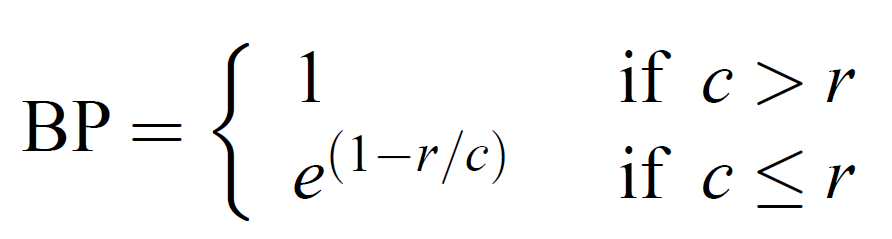
- r : 정답 문장 길이
- c : 예측 문장 길이
여러 문장에 대해 BLEU Score를 계산할 때는 아래와 같이 계산하면 된다.
$p_{n}=\frac{\sum_{sentence}^{}정답 문장에 존재하는지 여부의 합계}{\sum_{sentence}^{}예측 문장의 n-gram 개수}$
'AI' 카테고리의 다른 글
| SVM (Support Vector Machine) 이란? (0) | 2024.11.27 |
|---|---|
| 랜덤 포레스트 (Random Forest) (0) | 2024.11.27 |
| 의사결정트리 (Decision Tree) (1) | 2024.11.27 |
| [pytorch] 순환신경망 (Recurrent Neural Network) 예제 코드 (0) | 2024.11.21 |
| [pytorch] 합성곱 신경망 (Convolution Neural Network) 예제 코드 (0) | 2024.11.20 |