![[HPC Lab] LSTM으로 Google Cluster Trace Data의 CPU rate 예측하기 - 데이터 전처리](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FnrXgs%2FbtsFBMg0rs3%2FAAAAAAAAAAAAAAAAAAAAAOAgy6USw4JgzqwylcXqIG4D_-5h8ExOvIGAEezVnRKc%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1764514799%26allow_ip%3D%26allow_referer%3D%26signature%3DESgTrdu7zno%252Fs4L8E4cgu7iE%252B9s%253D)
Cluster Autometic DR 논문의 공저자를 목표로 대장정을 시작한다.
아래의 google 공식 github에서 cluter trace data 2011 (version 2) 를 이용하여 CPU rate에 관련된 데이터를 만들고자 한다.
https://github.com/google/cluster-data
GitHub - google/cluster-data: Borg cluster traces from Google
Borg cluster traces from Google. Contribute to google/cluster-data development by creating an account on GitHub.
github.com
Alibaba의 데이터셋도 고려하였지만, 데이터셋 크기가 크고 feature가 최대한 많은 google의 데이터셋을 택했다.
데이터셋 다운로드
gsutilcp-Rgs://clusterdata-2011-2/ destination-directory해당 데이터셋을 서버에 마운트된 nfs 저장소에 저장한 후 압축을 풀어줬다.
압축을 풀면 2.2TB가량의 어마무시한 데이터셋이 등장하니 충분한 공간을 확보해 둘 필요가 있다.
데이터셋 구조
해당 데이터셋은 2011년 5월, 총 29일간 약 12500대의 machine, 65만개의 job, 2천만개의 task를 가진 단일 클러스터를 추적한 데이터이다.
각 Unit간의 포함 관계는 machine > job > task 이다.
그래서 Unit 별로 데이터셋 내부에 폴더가 나뉘어져 있다.
CPU 사용량과 관련된 feature는 task_usage 폴더 내부의 파일에만 존재한다..
그리고 제일 골치아픈 부분은 해당 데이터셋이 규칙적인 시계열 데이터가 아니라는 것이다. 각 단위가 동작할때만 추적되어 있다.
그럼 전체 클러스터의 CPU 사용량은? -> task_usage의 하위 파일들의 cpu_rate feature를 시간별로 전부 합산하면 된다.
여기서부터 노가다가 시작된다.
전처리
이 웅장한 파일 갯수와 크기가 보이는지... 해당 csv 파일을 한번 까보자.
(데이터셋에 관한 document가 이미 있지만, 데이터는 직접 까보는게 필수..)
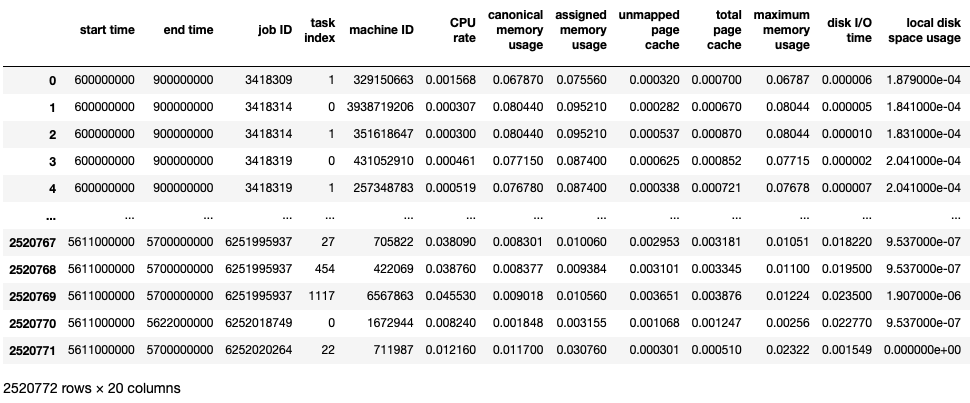
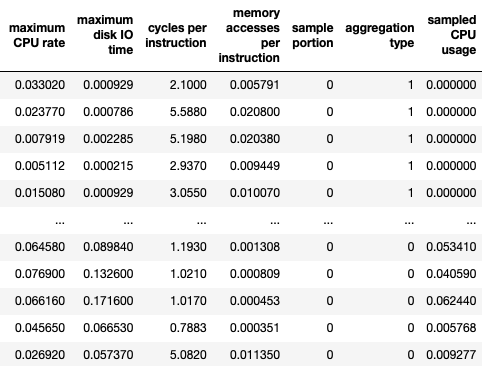
자.. 이제 여기서 맛있어 보이는 feature를 선정한다.
원래 이런 판단은 컴퓨터에게 맡겨야 하지만, dataset의 크기가 너무 방대해서 feature간 연관성 검사를 할 엄두조차 나지 않았다.
그래서 나만의 기준으로 필요없는 feature를 Drop했다. (이러한 대용량 데이터셋을 처음 만져보는지라..)
feature Drop과 시계열 데이터로 만들기 위한 시간 순 정렬 과정을 먼저 해보겠다.
아래의 코드로 진행하였다.
import pandas as pd
import glob
from tqdm import tqdm
file_pattern = 'part-*.csv'
result_df = pd.DataFrame()
file_list = glob.glob(file_pattern)
for file in tqdm(file_list, desc="Processing Files"):
df = pd.read_csv(file)
selected_columns = df[['start time', 'end time', 'CPU rate', 'canonical memory usage']]
result_df = pd.concat([result_df, selected_columns], ignore_index=True)
result_df = result_df.sort_values(by='start time', ascending=True)
result_df = result_df.reset_index(drop=True)
result_df['start time'] = result_df['start time'] / 1000000
result_df['end time'] = result_df['end time'] / 1000000
result_df.to_csv('original_cpu_memory.csv')
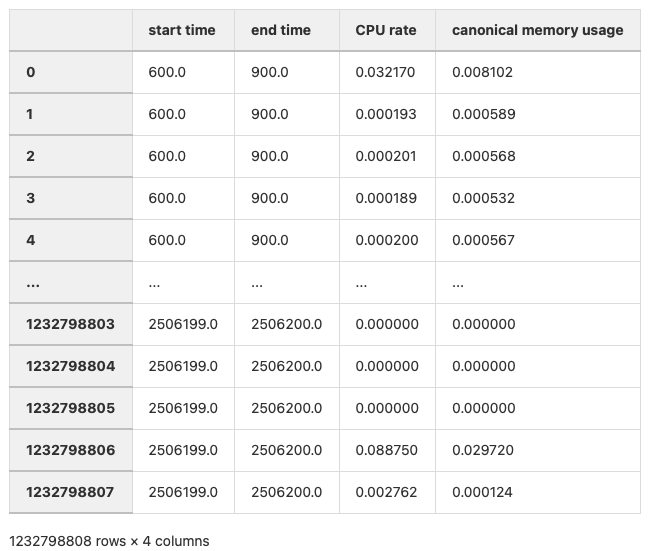
좋다.. 500개의 csv파일을 전부 한 파일로 만들었다.
다음은 시간만 오래 걸리는 aggregation 작업이다. 아래의 코드로 진행하여 10분 주기의 시계열 데이터셋으로 만들었다.
정말 많은 연산이 필요한데, GPU를 사용해 연산하기 위해 cudf, cupy 라이브러리의 사용을 시도했으나.. 왜인지 모를 이유로 계속 커널이 죽고 gpu도 잘 잡지 못해서 기존 프로그래밍 방식으로 진행하였다.
import cudf
import cupy as cp
import numpy as np
import pandas as pd
from tqdm import tqdm
df = pd.read_csv('original_cpu_memory.csv')
df = df.drop(columns=['Unnamed: 0'])
aggregation = pd.DataFrame({'timestamp': np.arange(600, 2506200, 600)})
aggregation['CPU rate'] = 0.0
aggregation['canonical memory usage'] = 0.0
timestamp_arr = np.asarray(aggregation['timestamp'])
CPU_rate_arr = np.asarray(aggregation['CPU rate'])
canonical_memory_usage_arr = np.asarray(aggregation['canonical memory usage'])
for index in tqdm(range(len(aggregation))):
timestamp = timestamp_arr[index]
mask = (df['start time'] <= timestamp) & (df['end time'] >= timestamp)
# cudf.Series의 broadcasting을 활용하여 GPU 상에서 연산 수행
CPU_rate_arr[index] = df['CPU rate'][mask].sum()
canonical_memory_usage_arr[index] = df['canonical memory usage'][mask].sum()
aggregation['CPU rate'] = CPU_rate_arr
aggregation['canonical memory usage'] = canonical_memory_usage_arr
aggregation.to_csv('aggregation_10min.csv')
10분 주기의 단일 클러스터에 대한 CPU와 Memory 사용량 데이터가 탄생하였다. (박수)
'AI' 카테고리의 다른 글
| 자기지도 학습 (0) | 2024.08.31 |
|---|---|
| 지도 학습 vs 비지도 학습 (0) | 2024.08.31 |
| CNN, RNN, GAN (0) | 2024.08.31 |
| Artificial Intelligence vs Machine Learning vs Deep Learning (0) | 2024.08.31 |
| [HPC Lab] LSTM으로 Google Cluster Trace Data의 CPU rate 예측하기 - 예측 (0) | 2024.03.07 |