![[HPC Lab] LSTM으로 Google Cluster Trace Data의 CPU rate 예측하기 - 예측](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2Fd224Bj%2FbtsFB8c6bTd%2FAAAAAAAAAAAAAAAAAAAAAJv-3QbKCdLwFLmodUQwr0ggH5unKoplUcxy0J5TtxYq%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1777561199%26allow_ip%3D%26allow_referer%3D%26signature%3Db%252B222BSKyeKLd2gbhbmaBa1ada0%253D)
https://welldonecode.tistory.com/96
[HPC Lab] LSTM으로 Google Cluster Trace Data의 CPU rate 예측하기 - 데이터 전처리
Cluster Autometic DR 논문의 공저자를 목표로 대장정을 시작한다. 아래의 google 공식 github에서 cluter trace data 2011 (version 2) 를 이용하여 CPU rate에 관련된 데이터를 만들고자 한다. https://github.com/google/clus
welldonecode.tistory.com
이전 포스팅에서 데이터 전처리를 완료하여 단일 클러스터의 CPU, Memory 사용량에 대한 10분 주기의 시계열 데이터를 생성하였다.
이번엔 기본적인 LSTM 모델을 생성하여 해당 데이터셋으로 CPU 사용량을 예측해보자.
datapoint가 4100개가 넘는 데이터다 보니 Sliding window 기법을 사용해야 했다.
import numpy as np
import pandas as pd
import tensorflow as tf
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import LSTM, Dense
from tensorflow.keras.losses import mse
from tensorflow.keras.metrics import RootMeanSquaredError, mean_squared_error, MeanAbsoluteError
from tensorflow.keras.optimizers import Adam
from sklearn.preprocessing import MinMaxScaler
from sklearn.metrics import r2_score
# TensorFlow 로그 메시지 숨기기
tf.compat.v1.logging.set_verbosity(tf.compat.v1.logging.ERROR)
# 데이터 로드 및 전처리
agg_5min = pd.read_csv('aggregation_5min.csv', engine='python')
agg_5min = agg_5min.drop(['Unnamed: 0', 'timestamp', 'canonical memory usage'], axis=1)
# 데이터 스케일링 (Min-Max 스케일링)
scaler = MinMaxScaler()
agg_5min['CPU rate'] = scaler.fit_transform(agg_5min['CPU rate'].values.reshape(-1, 1))
# 슬라이딩 윈도우 설정
window_size = 3 # 윈도우 크기 (조정 가능)
step_size = 1 # 윈도우 이동 간격 (조정 가능)
# 슬라이딩 윈도우를 사용하여 데이터 생성
def create_sliding_window_data(data, lookback_time=5, predict_time=2):
X = []
y = []
for i in range(len(data) - (lookback_time - 1) - predict_time):
x_window = data['CPU rate'].iloc[i:i+lookback_time].values
y_value = data['CPU rate'].iloc[i+lookback_time+predict_time-1]
X.append(x_window)
y.append(y_value)
return np.array(X), np.array(y)
x, t = create_sliding_window_data(agg_5min)
# 데이터 분할 (학습 및 테스트 데이터)
x_train, x_test, t_train, t_test = train_test_split(x, t, test_size=0.2, shuffle=False)
# LSTM 모델 생성
cell_size = 256
timesteps = 5
feature = 1
model = Sequential(name="CPU_LSTM")
model.add(LSTM(cell_size, input_shape=(timesteps, feature), return_sequences=True))
model.add(LSTM(cell_size))
model.add(Dense(1))
model.compile(loss=mse, optimizer=Adam(learning_rate=0.0001), metrics=[RootMeanSquaredError(), MeanAbsoluteError()])
model.summary()
model = Sequential(name="CPU_LSTM")
model.add(LSTM(cell_size, input_shape=(timesteps, feature), return_sequences=True))
model.add(LSTM(cell_size))
model.add(Dense(1))
model.compile(loss=mse, optimizer=Adam(learning_rate=0.0001), metrics=[RootMeanSquaredError(), MeanAbsoluteError()])
model.summary()
# 모델 학습
history = model.fit(x_train, t_train, epochs=100, batch_size=64, validation_data=(x_test, t_test), verbose=1)
# 모델 평가
y_pred = model.predict(x_test)
t_test_reset = scaler.inverse_transform(t_test.reshape(-1, 1)) # t_test를 2D 배열로 변환
y_pred_reset = scaler.inverse_transform(y_pred) # y_pred는 이미 2D 배열이므로 추가 변환이 필요 없음
r2_reset = r2_score(t_test_reset, y_pred_reset)
loss_reset = mean_squared_error(t_test_reset, y_pred_reset)
rmse_reset = np.sqrt(mean_squared_error(t_test_reset, y_pred_reset))
mae_reset = mean_absolute_error(t_test_reset, y_pred_reset)
mape_reset = np.mean(np.abs((t_test_reset - y_pred_reset) / t_test_reset)) * 100
r2_scale = r2_score(t_test, y_pred)
loss_scale = mean_squared_error(t_test, y_pred)
rmse_scale = np.sqrt(mean_squared_error(t_test, y_pred))
mae_scale = mean_absolute_error(t_test, y_pred)
mape_scale = np.mean(np.abs((t_test - y_pred) / t_test)) * 100
print('===Decode Data===')
print('Test Loss (MSE):', loss_reset)
print('Test RMSE:', rmse_reset)
print('Test MAE:', mae_reset)
print('R-squared (R^2):', r2_reset)
print('Test MAPE:', mape_reset)
print('===Scaled Data===')
print('Test Loss (MSE):', loss_scale)
print('Test RMSE:', rmse_scale)
print('Test MAE:', mae_scale)
print('R-squared (R^2):', r2_scale)
print('Test MAPE:', mape_scale)
# 예측 결과 시각화
plt.figure(figsize=(12, 6))
plt.plot(t_test, label='Actual', color='blue')
plt.plot(y_pred, label='Predicted', color='red', linestyle='--')
plt.xlabel('Time')
plt.ylabel('CPU Rate')
plt.title('CPU Rate Prediction')
plt.legend()
plt.show()
# 예측 결과 시각화
plt.figure(figsize=(12, 6))
plt.plot(t_test_reset, label='Actual', color='blue')
plt.plot(y_pred_reset, label='Predicted', color='red', linestyle='--')
plt.xlabel('Time')
plt.ylabel('CPU Rate')
plt.title('CPU Rate Prediction')
plt.legend()
plt.show()
자.. 과연 예측이 잘 됐을까? 성능 지표부터 확인해 보자.
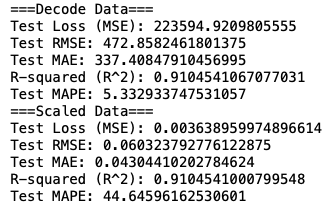
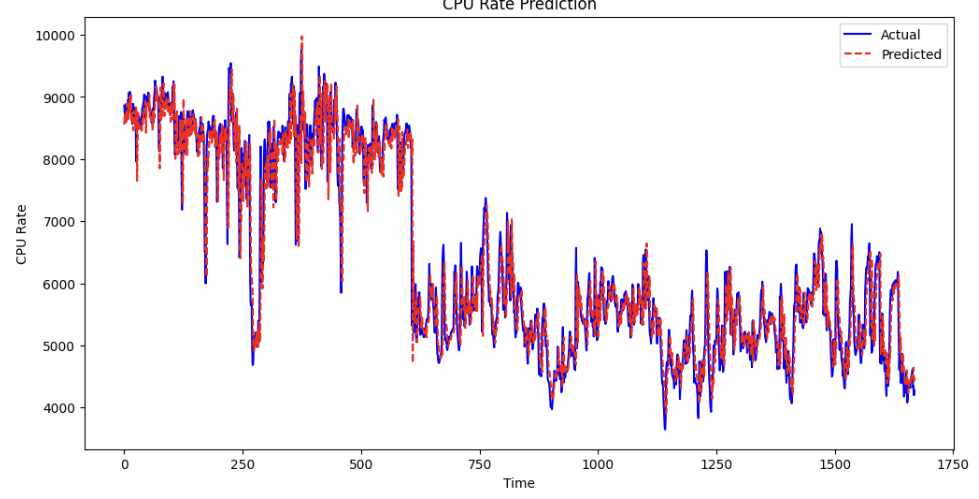
기본적인 LSTM 모델만으로도 CPU rate에 대한 예측이 나쁘지 않게 됐다.
근데 여기서 의문이 든다. 이전 값을 그대로 10분 뒤로 가져왔을 때와 내가 LSTM으로 예측했을때의 성능 차이가 얼마 없지 않을까...?
다양한 실험 조건으로 테스트 해봤다.
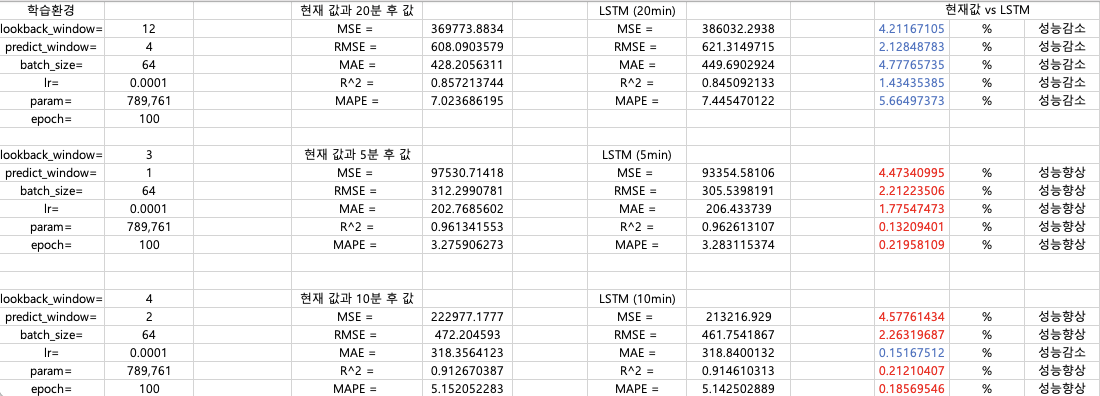
MSE는 원본 데이터의 값이 크기 때문에 별로 의미 없을 것 같고..
RMSE로 따졌을 때 2.2%.. MAPE는 0.1~0.2%.. 정도
20분 후의 값은 기본적인 LSTM으로는 역시나 잘 맞추지 못한다.
Cluster Automatic DR with LSTM 관련 연구 보조로 해당 프로젝트를 진행하였는데,
아직 미흡하지만 일단 아카이브에 논문을 올렸다.
https://arxiv.org/abs/2402.02938
Design and Implementation of an Automated Disaster-recovery System for a Kubernetes Cluster Using LSTM
With the increasing importance of data in the modern business environment, effective data man-agement and protection strategies are gaining increasing research attention. Data protection in a cloud environment is crucial for safeguarding information assets
arxiv.org
아직 revision 할게 많아서 mdpi에 제출할 수 있을지는 미지수다..
'AI' 카테고리의 다른 글
| 자기지도 학습 (0) | 2024.08.31 |
|---|---|
| 지도 학습 vs 비지도 학습 (0) | 2024.08.31 |
| CNN, RNN, GAN (0) | 2024.08.31 |
| Artificial Intelligence vs Machine Learning vs Deep Learning (0) | 2024.08.31 |
| [HPC Lab] LSTM으로 Google Cluster Trace Data의 CPU rate 예측하기 - 데이터 전처리 (2) | 2024.03.07 |